何故やったか
pandas.DataFrameに1行ずつデータを書き出して行く処理を書いていたんですが、10万行ほど書き出すと結構遅くなっちゃいました。今後行数が増える予定なので、これを期にどう書くと早くなるか確認しておく事にしました。
やったこと
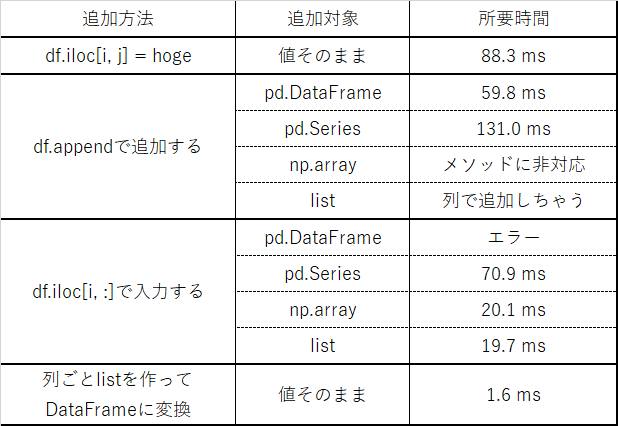
- pandas.DataFrame.iloc[i, j] = hoge で1つずつ記入
- pandas.DataFrame.append(hoge) で1行まとめて追加
- pandas.DataFrame.iloc[i,:] = hoge で1行まとめて追加
- 1列ずつリストで作ってDataFrameに変換する※ ※ 2018.11/12 kishiyamaさんに教えて頂いたやり方を追記
試した環境
windows10 64bit
cpu: Ryzen7 1700X
gpu: GTX1080Ti
python3.6
jupyter 1.0.0
jupyter-client 5.2.3
jupyter-console 6.0.0
jupyter-core 4.4.0
Microsoft Edge 17.17134
結論
1列ずつリストで作ってDataFrameに変換するやり方がメチャメチャ速い!
df.iloc[i, :] = listまたは df.iloc[i, :] = numpy.array が速い
※ 2018.11/12 kishiyamaさんに教えて頂いたやり方がめっちゃ速いので修正
コードと実行結果
1. pd.DataFrame.iloc[i, j] = hoge で1つずつ記入
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'], index=range(100))
for i in range(100):
log.iloc[i,0] = 'test'
log.iloc[i,1] = ''
log.iloc[i,2] = ''
log.iloc[i,3] = 'test'
log.iloc[i,4] = 'test'
return(log)
%timeit log = test()
88.3 ms ± 2.64 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
遅い
2-1. pd.DataFrame.append(hoge) で1行まとめて追加 (pandas.DataFrame)
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'])
for _ in range(100):
addRow = pd.DataFrame(['test','','','test','test'], index=log.columns).T
log = log.append(addRow)
return(log)
%timeit log = test()
59.6 ms ± 1.62 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
ちょっと速くなった
2-2. pd.DataFrame.append(hoge) で1行まとめて追加 (pandas.Series)
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'])
for _ in range(100):
addRow = pd.Series(['test','','','test','test'], index=log.columns)
log = log.append(addRow, ignore_index=True)
return(log)
%timeit log = test()
131 ms ± 3.96 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
逆に遅くなっちゃう
3-1. pandas.DataFrame.iloc[i,:] = hoge で1行まとめて追加 (pandas.Series)
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'], index=range(100))
for i in range(100):
addRow = pd.Series(['test','','','test','test'])
log.iloc[i,:] = addRow
return(log)
%timeit log = test()
70.4 ms ± 2.33 ms per loop (mean ± std. dev. of 7 runs, 10 loops each)
3-2. pandas.DataFrame.iloc[i,:] = hoge で1行まとめて追加 (numpy.array)
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'], index=range(100))
for i in range(100):
addRow = np.array(['test','','','test','test'])
log.iloc[i,:] = addRow
return(log)
%timeit log = test()
20.1 ms ± 108 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
速い
3-3. pandas.DataFrame.iloc[i,:] = hoge で1行まとめて追加 (list)
def test():
log = pd.DataFrame([], columns=['A','B','C','D','E'], index=range(100))
for i in range(100):
addRow = ['test','','','test','test']
log.iloc[i,:] = addRow
return(log)
%timeit log = test()
19.8 ms ± 216 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)
速い
4. 1列ずつリストで作ってDataFrameに変換する
def test():
a = []
b = []
c = []
d = []
e = []
for i in range(100):
a += ['test']
b += ['']
c += ['']
d += ['test']
e += ['test']
return pd.DataFrame(
data={'A': a, 'B': b, 'C': c, 'D': d, 'E': e},
columns=['A', 'B', 'C', 'D', 'E']
)
%timeit log = test()
1.58 ms ± 18.4 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)
めっちゃ速
というわけで、リストで足し合わせておいてpd.DataFrame()に変換するやり方がめっちゃ速です。以前やってたやり方より50倍速いので、前回3日待った処理が1時間ちょいで完了できそう!